引言
Elasticsearch(简称ES)是一个基于Apache Lucene构建的分布式、RESTful风格的搜索和分析引擎。它以其高效的全文检索、近实时搜索和强大的分布式能力,在大数据存储、日志分析、企业搜索等场景中广泛应用。理解ES的数据存储与查询基本原理,对于有效利用其数据处理和存储服务至关重要。
1. 核心数据结构与索引
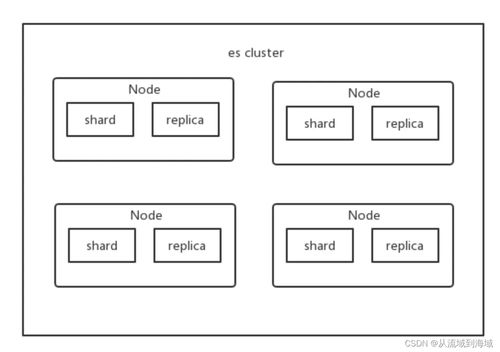
ES的核心概念围绕“索引”展开。在ES中,一个索引可以类比为传统关系型数据库中的一个数据库。它包含多个分片,每个分片是一个独立的Lucene索引,负责存储数据的一部分。
- 文档:ES中存储的基本数据单元,以JSON格式表示。每个文档包含多个字段。
- 映射:定义文档的字段类型和属性,决定了数据如何被索引和存储。例如,文本字段会进行分词处理,而数值或日期字段则按原样存储。
- 倒排索引:ES查询高效的核心。它记录了每个词项出现在哪些文档中,并包含位置等信息。这使得全文检索可以快速定位包含特定词汇的文档,而非逐条扫描。
2. 数据写入与存储流程
当数据写入ES时,会经历一系列处理步骤:
- 文档接收:客户端通过HTTP REST API发送JSON文档到ES集群。
- 路由与分片:ES根据文档的ID或路由键,通过哈希算法确定其应归属的主分片。每个索引被分成多个主分片,以实现水平扩展和并行处理。
- 索引处理:文档到达目标分片后,会进行以下操作:
- 分析:对文本字段进行分词、归一化(如转为小写)、去除停用词等,生成词项。
- 构建倒排索引:将词项及其在文档中的信息添加到倒排索引结构中。
- 刷新与提交:
- 刷新:默认每1秒执行一次,将内存中的索引数据写入文件系统缓存,使新文档可被搜索(近实时性)。
- 提交:定期将多个段合并,并写入磁盘持久化,优化存储和查询性能。
- 副本同步:每个主分片可以有多个副本分片。写入操作首先在主分片上完成,然后异步复制到副本分片,确保数据冗余和高可用性。
3. 数据查询基本原理
ES的查询过程涉及多个阶段的协作,以实现快速且相关的搜索结果。
- 查询解析:查询请求(如匹配查询、范围查询等)被解析成查询DSL(领域特定语言)表示。
- 分发与执行:
- 查询请求被发送到协调节点,该节点将查询转发给相关分片(主分片或副本)。
- 每个分片独立执行查询,在本地倒排索引中查找匹配的文档,并根据相关性评分算法(如TF-IDF、BM25)计算文档得分。
- 结果合并:协调节点收集所有分片的局部结果,进行全局排序、过滤和聚合,生成最终结果集。
- 返回结果:将排序后的文档(通常包含ID、得分和源数据)返回给客户端。
4. 数据处理与存储服务的优化
基于上述原理,ES在数据处理和存储服务方面提供了多项优化特性:
- 近实时搜索:通过定期刷新机制,数据在写入后约1秒内即可被搜索,平衡了性能与实时性。
- 分布式架构:分片和副本机制支持水平扩展,处理海量数据和高并发查询。
- 聚合分析:支持丰富的聚合功能(如统计、分组、嵌套聚合),适用于数据分析和报表生成。
- 冷热数据分层:结合ILM(索引生命周期管理),可将热数据存储在SSD上以优化查询性能,冷数据迁移到HDD以降低成本。
- 数据压缩:使用高效编码和压缩算法(如LZ4、DEFLATE)减少存储空间占用。
5. 应用场景与
ES的数据存储与查询设计,使其特别适合以下场景:
- 全文检索:网站搜索、文档检索等,利用倒排索引实现快速关键词匹配。
- 日志与指标分析:通过集成如Logstash、Beats等工具,实现日志的实时采集、存储和可视化分析。
- 商业智能:结合Kibana进行数据探索和仪表板展示,支持复杂的聚合查询。
Elasticsearch通过其独特的倒排索引、分布式分片和近实时处理机制,提供了高效、可扩展的数据处理与存储服务。深入理解这些基本原理,有助于用户更好地设计索引、优化查询,并在实际应用中充分发挥其潜力,满足多样化的数据管理需求。